
Art Style Transfer Using Different Neural Networks
Art Style transfer (A comparison between models)
Art Style Transfer consists in the transformation of an image into a similar one that seems to have been painted by an artist. If we are Vincent van Gogh fans, and we love German Shepherds, we may like to get a picture of our favorite dog painted in van Gogh’s Starry Night fashion.

Introduction
Art Style Transfer consists in the transformation of an image into a similar one that seems to have been painted by an artist.
If we are Vincent van Gogh fans, and we love German Shepherds, we may like to get a picture of our favorite dog painted in van Gogh’s Starry Night fashion.

Image by author

Starry Night by Vincent van Gogh, Public Domain
The resulting picture can be something like this:

Image by author
Instead, if we like Katsushika Hokusai’s Great Wave off Kanagawa, we may obtain a picture like this one:

The Great wave of Kanagawa by Katsushika Hokusai, Public Domain
{kind=link}

Image by author
And something like the following picture, if we prefer Wassily Kandinsky’s Composition 7:

Compositions 7 by Wassily Kandinsky, Public Domain
{kind=link}

Image by author
These image transformations are possible thanks to advances in computing processing power that allowed the usage of more complex neural networks.
Before continuing, you may like to see how to implement a bare bones Neural Network using python without any complex framework Clicking Here
The Convolutional Neural Networks (CNN), composed of a series of layers of convolutional matrix operations, are ideal for image analysis and object identification. They employ a similar concept to graphic filters and detectors used in applications like Gimp or Photoshop, but in a much powerful and complex way.
A basic example of a matrix operation is performed by an edge detector. It takes a small picture sample of NxN pixels (5x5 in the following example), multiplies it’s values by a predefined NxN convolution matrix and obtains a value that indicates if an edge is present in that portion of the image. Repeating this procedure for all the NxN portions of the image, we can generate a new image where we have detected the borders of the objects present in there.

Image by author
The two main features of CNNs are:
- The numeric values of the convolutional matrices are not predefined to find specific image features like edges. Those values are automatically generated during the optimization processes, so they will be able to detect more complex features than borders.
- They have a layered structure, so the first layers will detect simple image features (edges, color blocks, etc.) and the latest layers will use the information from the previous ones to detect complex objects like people, animals, cars, etc.
This is the typical structure of a Convolutional Neural Network:
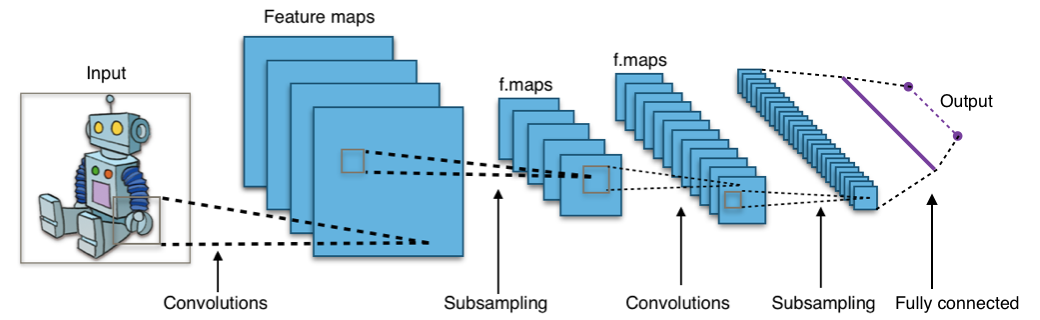
Image by Aphex34 / CC BY-SA 4.0
{kind=link}
Thanks to papers like “Visualizing and Understanding Convolutional Networks”[1] by Matthew D. Zeiler, Rob Fergus and “Feature Visualization”[12] by Chris Olah, Alexander Mordvintsev, Ludwig Schubert, we can visually understand what features are detected by the different CNN layers:

Image by Matthew D. Zeiler et al. “Visualizing and Understanding Convolutional Networks”[1], usage authorized
The first layers detect the most basic features of the image like edges.

Image by Matthew D. Zeiler et al. “Visualizing and Understanding Convolutional Networks”[1], usage authorized
The next layers combine the information of the previous layer to detect more complex features like textures.

Image by Matthew D. Zeiler et al. “Visualizing and Understanding Convolutional Networks”[1], usage authorized
Following layers, continue to use the previous information to detect features like repetitive patterns.

Image by Matthew D. Zeiler et al. “Visualizing and Understanding Convolutional Networks”[1], usage authorized
The latest network layers are able to detect complex features like object parts.

Image by Matthew D. Zeiler et al. “Visualizing and Understanding Convolutional Networks”[1], usage authorized
The final layers are capable of classifying complete objects present in the image.
The possibility of detecting complex image features is the key enabler to perform complex transformations to those features, but still perceiving the same content in the image.
Independent image optimization
One of the most important papers regarding Art Style Transfer is “A Neural Algorithm of Artistic Style”[2] by Leon A. Gatys, Alexander S. Ecker, Matthias Bethge.
Its main finding was that the Content of a natural image and its Style can be separated and processed independently of each other, which allows us to “extract” the style from a classic art paint and apply it to our own images.
Many of the other Neural Style Transfer models discussed here took this idea and expanded it with faster and more complex networks, but still using this foundation.
Gatys et al. model is based in a VGG-19[3] neural network, which is commonly used for visual object recognition and rivals human performance.

Image by author
Then, it uses pieces of it to define some functions:
- A Content Loss function, that calculates how the content of the generated image differs from the content of our original image. To compare the Content, instead of comparing the image pixels, it checks the values of one of the CNN highest layers of the Input Image and the values of that layer for the Output Image. This will allow us to generate different images that will contain similar objects in them.
- A Style Loss function, that calculates how the style of the generated image differs from the style of the classic art paint (or whatever style image we choose to use). To compare Styles, a different approach is required. It takes layers at different levels (to compare features of different complexity) and for each layer, a matrix (Gram matrix) with the correlation between the detected features is created. This matrix indicates which features occur simultaneously (like finding that horizontal lines always have X color, etc). The Style Loss is calculated as the distance between the Gram matrices of the layers of the Style Image and the Gram matrices of the layers in the Output Image. This allows us to apply features from the simple ones, like blocks of some color, to the most complex ones like waves or the artist brushstroke.
- A Total Loss function that takes into account both the Content Loss and the Style Loss.
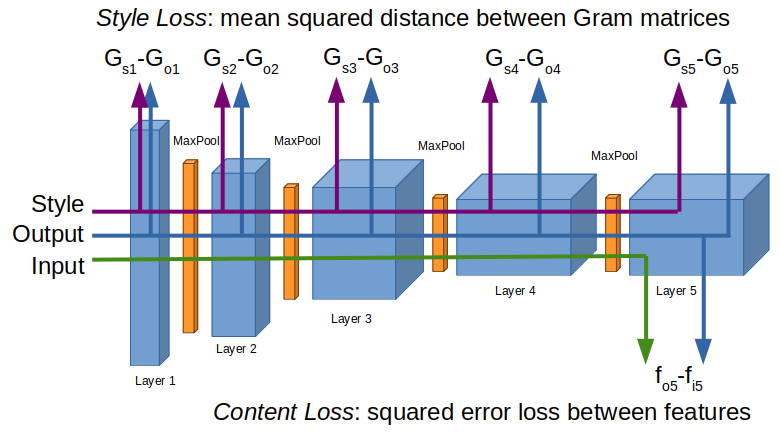
Image by author
Then it runs several optimization rounds (thousands or more) that will introduce changes in our working image that will decrease the Total Loss, thus producing a mix between our photo and the painting style.
All the previous German Shepherd artistic images were generated using this method.
You can also generate your own artistic pictures using this method going to the artcopypaste.com web site.
Advantages:
- Works with arbitrary styles and images of any size (limited only by the GPU memory used in the process).
- Does not require to pre-train the neural network (it uses the VGG19 ImageNet weights used for object detection).
- There are examples available for the main deep learning frameworks: PyTorch, Tensorflow, Keras, etc.
Disadvantages:
- It takes a long time to produce results, in the order of several minutes on a medium-range GPU.
- It needs to store the VGG pre-trained weights data (550 MB).
Pre-trained networks for a single style transfer
These networks tackle the main disadvantage of models like the previously described have: The time it takes to produce an artistic image.
They are based in models like the one described in the paper “Perceptual Losses for Real-Time Style Transfer and Super-Resolution”[4] by Justin Johnson, Alexandre Alahi, Li Fei-Fei.
These models pre-train a CNN with a specific style, which can take a few hours in a GPU, and then these networks can be used to apply the selected style to any image nearly in real-time and also to apply styles to movies in a few minutes.
They are composed of two CNNs:
- An optimizable Image Transformation Network, that takes the Original Image and generates the new Artistic Image, following the Encoder-Decoder design. An Image is first reduced to a set of high-level features that then can be expanded to recreate the image, but in this case, with an artistic style applied.
- A fixed Loss Network, that’s used to measure the “Perception Loss”, or how the generated image differs from the original despite changing its style. This Loss is similar to Gatys et al[2] Total Loss function (Content Loss + Style Loss) but it’s calculated using a pre-trained VGG16[3] network instead of a VGG19 network.
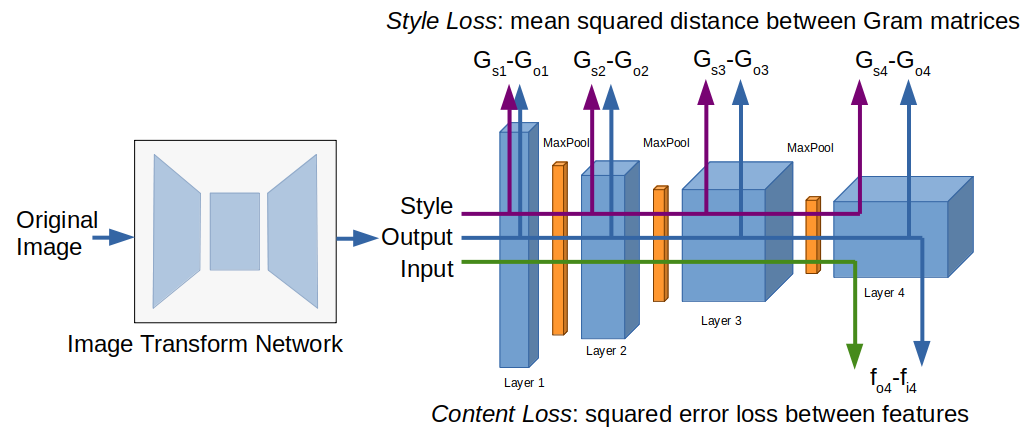
Image by author
The structure of the Image Transform Network is similar to:
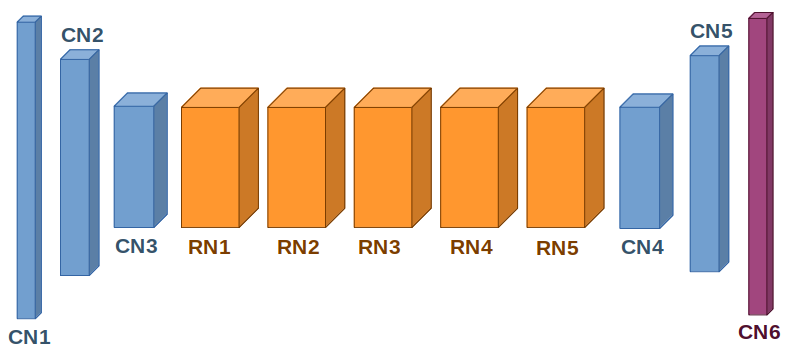
Image by author
- The network structure follows the guidelines from Radford et al[5]
- C1–3 are convolutions with a step 2 striding without pooling, to down-sample the image, and with Batch normalization and ReLU activation.
- RN1–5 are ResNets[6] for high-level image features recognition. ResNets proved to be faster than VGG at image recognition problems.
- C4–6 are convolutions with ½ striding without pooling, for image up-sampling, with Batch normalization and ReLU activation, except the last layer that uses Tanh activation to generate pixel values between 0 and 255.
- Convolutions C1 and C6 use 9x9 kernels, C2–5 use 3x3 kernels.
This image down-sampling and up-sampling help detect higher-level features of the images. In a way, it works like a lossy compression but for image high-level features (not pixels or colors as in a JPEG image).
Using the same images and styles as before, it will produce the following results:

Image by author, starry night style

Image by author, great wave style

Image by author, composition 7 style
Advantages:
- Once trained, the Image Transform Network is really fast applying the style for which it was trained to any type of original image. It works in the order of tens of seconds in a mid-range GPU.
Disadvantages:
- It takes much more time to train as it needs to train the network against an image dataset.
- Not only it needs the weights data for the VGG (550 MB), but also needs the image dataset for training (for example, the COCO 2014 dataset that contains 82,700 images and needs 13.7 GB of storage)
Pre-trained networks for arbitrary style transfer
These networks also generate a pre-trained model, but not limited to only one style, this model aims to be able to reproduce any style present in the style image.
One way to create this type of network model is described in the paper “Exploring the structure of a real-time, arbitrary neural artistic stylization network”[7] by Golnaz Ghiasi, Honglak Lee, Manjunath Kudlur, Vincent Dumoulin, Jonathon Shlens.
Another very similar model, is described in “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization”[8] by Xun Huang, Serge Belongie.
This model consists of three Neural Networks:
- A Style Transfer Network (similar to Johnson et al[4] Image Transfer Network)
- A Loss Network (similar to Johnson et al. VGG16[3])
- And adds a Style Prediction Network (Inception V3[9]).

Image by author
Golnaz Ghiasi et al.[7] paper expands the initial work described in “A Learned Representation For Artistic Style”[10] by Vincent Dumoulin, Jonathon Shlens, Manjunath Kudlur, which implemented a model similar to Johnson et al[4], but by manipulating the normalization parameters of the Style Transform Network it was capable of applying 32 painting styles to the images.
Thanks to the addition of the Style Prediction Network, the model is able to apply any number of styles, even styles for which it was not trained. This network produces a vector of normalization parameters S that represents the detected Style present in the Style Image and applies them to the Style Transfer network to generate the Artwork.
To train this model, not only requires a large image dataset to use as content for training Style Transfer Network (in this case, the ImageNet dataset consisting of 14 million images) but also a large style image dataset to train the Style Prediction Network (in this case the Painter by Numbers dataset, consisting of 80.000 art paintings and the Describable Textures dataset, composed of 5600 textures).
Fortunately, there are pre-trained models readily available that can be used directly:
- A first version, available in Tensorflow Hub with only 39 MB in weights data size, and can produce the following images: https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/1

Image by author, starry night style

Image by author, great wave style

Image by author, composition 7 style
- A Second updated version, of 82 MB in size, also available in Tensorflow Hub: https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2

Image by author, starry night style

Image by author, great wave style

Image by author, composition 7 style
You can also test your own images with this model in the artcopypaste.com web site.
Advantages:
- This model is very fast. With the pre-trained model just with 1 pass through the Style Transfer Network and the Style Prediction Network, it produces the artistic image output.
Disadvantages:
- It needs a large image dataset and time to train. But fortunately, pre-trained models are available and ready to use.
- They do not generate results with the same high details as Gatys et al[2] or Johnson et al[4] due to the limited resolution of the styles used for training, but they still are very pleasant results.
Universal style transfer with Encoder-Decoder networks
This model is detailed in the paper “Universal Style Transfer via Feature Transforms”[11] by Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, Ming-Hsuan Yang
It tries to discard the need to train the network on the style images while still maintaining visual appealing transformed images.
It first trains a series of Decoder networks that connect to the different layers of a VGG network. The VGG network acts as an encoder. It is loaded with the ImageNet weights and fixed. Each decoder structure has the inverse structure of the VGG up to the point where the decoder connects to the encoder.
Using an image dataset, the decoders are trained to regenerate the original image feed to the VGG. And once they have been trained, their weights are fixed for the rest of the process.

Image by author
This produces a set of Encoders-Decoders that translate the original image to features with different levels of complexity, but that is capable of reconstructing the original image, either performing a single level transformation or, for better generation quality, a multi-level transformation.
For single-level transformation:
- Both the Content and Style images are encoded through the VGG.
- The features of both images are extracted from a specific layer.
- Then, a Whitening and Coloring transformation is applied to those features.
- The result of the WCT then is fed to the corresponding Decoder network to generate the stylized image.

Image by author
In practice, the whitening process helps capture content features present in the content and style images. And the coloring process, on the other hand, helps capture style features. Finally, the process blends the content and style features given specified relative weights to each one. This blend is what is then fed to the Decoder to continue the process.
For a multi-level optimization:
- The original image and the style image are fed to the VGG.
- The features of both images are extracted from the fifth layer.
- The whitening and coloring transformations are performed in the features and then fed to the fifth Decoder.
- The output of that decoder is then fed, along with the style image, again into the VGG.
- Then we take the features of both images, this time, from the fourth layer.
- The features are processed with the whitening and coloring transformations and then fed to the fourth Decoder.
- Similarly, these steps are repeated until we get a generated image from the first Decoder.
- This generated image is our final artistic image.
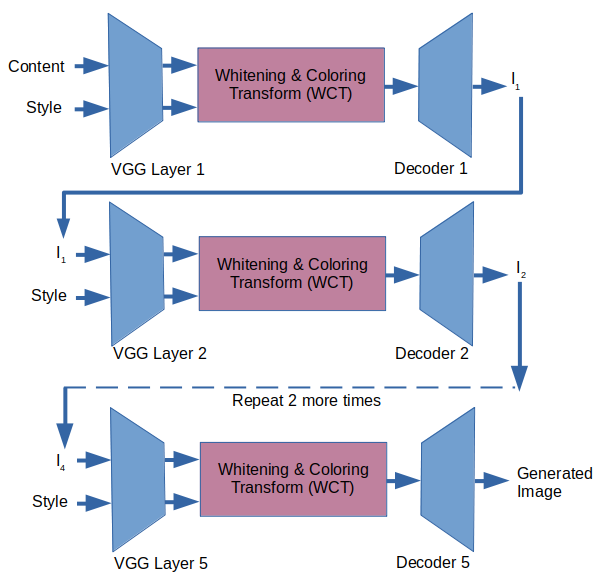
Image by author
Some examples of this model are the following:

Image by author, starry night style

Image by author, great wave style

Image by author, composition 7 style
Advantages:
- This model is fast. With the five passes (one through each encoder-decoder) it produces the artistic image output.
Disadvantages:
- It needs large image datasets and time to train each of the five decoder networks, but this is needed just only one time, but the paper even includes pre-trained weights in the code samples.
Final Thoughts
This work is far from describing all the existing neural network models to perform the fascinating process of art style transfer, that is in constant evolution.
The best example is Gatys et al. separation between the Content and the Style of an image, that was taken and expanded by almost all other models.
I also just wanted to show, using a few examples, how we can get a deeper understanding of what we consider an object in an image, despite all the possible transformations in color and form it can suffer, and get a better idea how we perceive the world we see around us.
Other related stories: Artificial Intelligence Beginnings (Build a Neural Network from scratch in Python)
References
1: Matthew D. Zeiler, Rob Fergus, “Visualizing and Understanding Convolutional Networks” (2013), https://arxiv.org/abs/1311.2901
2: Leon A. Gatys, Alexander S. Ecker, Matthias Bethge, “A Neural Algorithm of Artistic Style” (2015), https://arxiv.org/abs/1508.06576
3: Karen Simonyan, Andrew Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition” (2014), https://arxiv.org/abs/1409.1556
4: Justin Johnson, Alexandre Alahi, Li Fei-Fei, “Perceptual Losses for Real-Time Style Transfer and Super-Resolution” (2016), https://arxiv.org/abs/1603.08155
5: Alec Radford, Luke Metz, Soumith Chintala, “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” (2015), https://arxiv.org/abs/1511.06434
6: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, “Deep Residual Learning for Image Recognition” (2015), https://arxiv.org/abs/1512.03385
7: Golnaz Ghiasi, Honglak Lee, Manjunath Kudlur, Vincent Dumoulin, Jonathon Shlens, “Exploring the structure of a real-time, arbitrary neural artistic stylization network” (2017), https://arxiv.org/abs/1705.06830
8: Xun Huang, Serge Belongie, “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization” (2017), https://arxiv.org/abs/1703.06868
9: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna, “Rethinking the Inception Architecture for Computer Vision” (2015), https://arxiv.org/abs/1512.00567
10: Vincent Dumoulin, Jonathon Shlens, Manjunath Kudlur, “A Learned Representation For Artistic Style” (2016), https://arxiv.org/abs/1610.07629
11: Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, Ming-Hsuan Yang, “Universal Style Transfer via Feature Transforms” (2017), https://arxiv.org/abs/1705.08086
12: Chris Olah, Alexander Mordvintsev, Ludwig Schubert, “Feature Visualization” (2017), https://distill.pub/2017/feature-visualization/